Abstract
We present Bioptic Agent, a tree-based, self-learning AI system for complete, non-hallucinated drug asset scouting across multilingual, global sources. Bio-pharmaceutical innovation has shifted: over 85% of patent filings now originate outside the U.S., with China accounting for nearly half of the global total and 30% of global drug development. In this high-stakes environment, failing to surface "under-the-radar" assets creates multi-billion-dollar risk for investors and BD teams. We construct a challenging completeness benchmark using a multilingual multi-agent pipeline and demonstrate that Bioptic Agent substantially outperforms all leading Deep Research AI agents.
Highlights
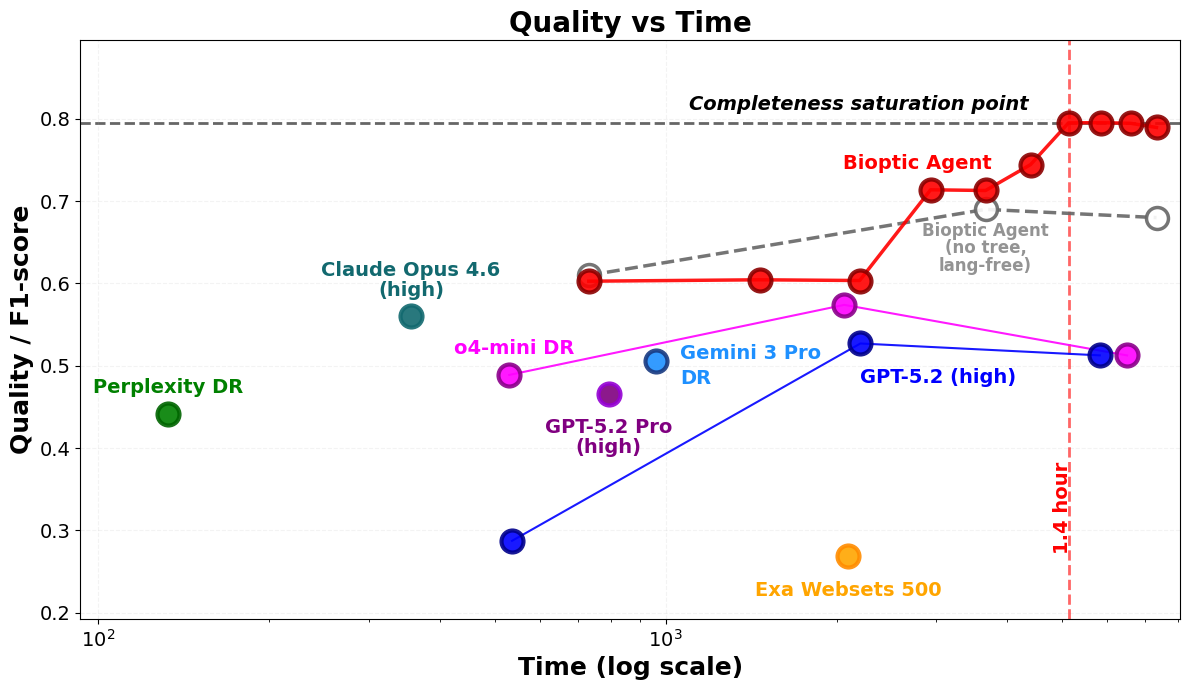
- Performance: Bioptic Agent achieves 79.7% F1 on the drug asset scouting benchmark
- Baselines beaten: Claude Opus 4.6 (56.2%), Gemini 3 Pro + Deep Research (50.6%), o4-mini Deep Research (48.9%), GPT-5.2 Pro (46.6%), Perplexity Deep Research (44.2%), Exa Websets (26.9%)
- Benchmark design: Multilingual, multi-agent pipeline; queries sourced from expert investors, BD, and VC professionals
- Grading: LLM-as-judge evaluation calibrated to expert opinions
- Scaling: Performance improves steeply with additional compute — more compute yields better results
- Coverage: Designed for non-English, non-U.S.-radar drug assets across regional patent and literature channels
Methods
Bioptic Agent is a tree-based, self-learning scouting system engineered around completeness and non-hallucination. Rather than compressing exploration into a single evolving narrative, the agent preserves the candidate set and its evidence as persistent artifacts, allocates compute to under-explored branches, and uses expert-aligned critic and validator signals to surface constraint violations and coverage gaps—converting these failure modes into targeted child directives that drive sustained recall growth. The system includes a Coach Agent (search history and error/gap analysis) and an Investigator Agent (automatic prompt refinement with parallel execution of conditioned directives). A debate-based weak-supervision approach is used to align the Precision Grader and Critic Agent on pseudo-labels, enabling consistent binary classification of (query, drug) match pairs.
Drug asset scouting benchmark
- Problem: General Deep Research AI agents still cannot match human experts at identifying all drug assets meeting complex, multi-constraint criteria—especially non-U.S., non-English-disclosed assets.
- Benchmark construction: Complex screening queries from expert investors and BD professionals, paired with ground-truth assets primarily outside U.S.-centric radar.
- Result: Bioptic Agent achieves 79.7% F1, with a steep compute-scaling curve; sequential "run-longer" scaffolds plateau earlier at lower quality.
- Outcome: A rigorous, completeness-first evaluation framework for the drug scouting problem—and a validated agent ready for real deal workflows.
Scientific rigor
- Benchmark designed to reflect real biopharma deal complexity, not curated toy tasks.
- Evaluation accounts for aliases, multilingual sources, and up-to-date attribute extraction via LLM-as-judge graders calibrated to expert opinion.
- Cross-policy consistency checks ensure the Precision Grader applies uniform criteria across all (query, drug) pairs.
- Builds on and expands Bioptic's prior work on LLM-based competitive landscape mapping in drug asset due diligence.
Links & availability
- Preprint (arXiv): https://arxiv.org/abs/2602.15019
- Try Bioptic Agent: https://pipeline.bioptic.io/
Citation
Hunt Globally: Wide Search AI Agents for Drug Asset Scouting in Investing, Business Development, and Competitive Intelligence. Vinogradova et al. arXiv preprint arXiv:2602.15019 (2026).
Authors & acknowledgements
A. Vinogradova and co-authors (full author list on arXiv).
We acknowledge the expert investors, BD, and VC professionals whose screening queries informed the benchmark design.