%20(1).png)
Answering it well is critical. Regulators use competitor drugs to set trial comparators. Investors use them to price risk. Companies use them to plan a strategy. Missing even one competitor can lead to failed trials, pricing challenges, or missed opportunities.
But the process is broken. Data is scattered across clinical trial registries, patents, publications, and press releases. Drug names come with endless aliases. Indications don’t map cleanly across ontologies. Information is fragmented, multimodal, and multilingual. Analysts spend days pulling this together—still never certain the list is complete.
At Bioptic, we asked a simple question: could an AI agent learn to do this job?
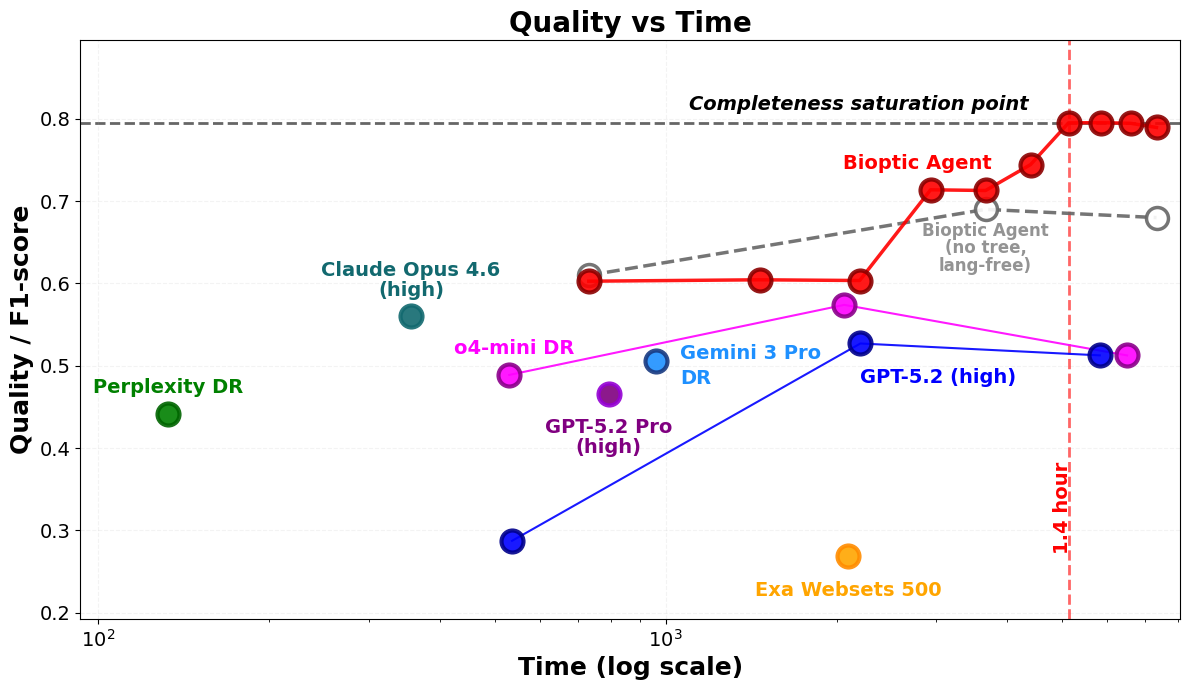
The first benchmark on competitive landscape mapping for bio
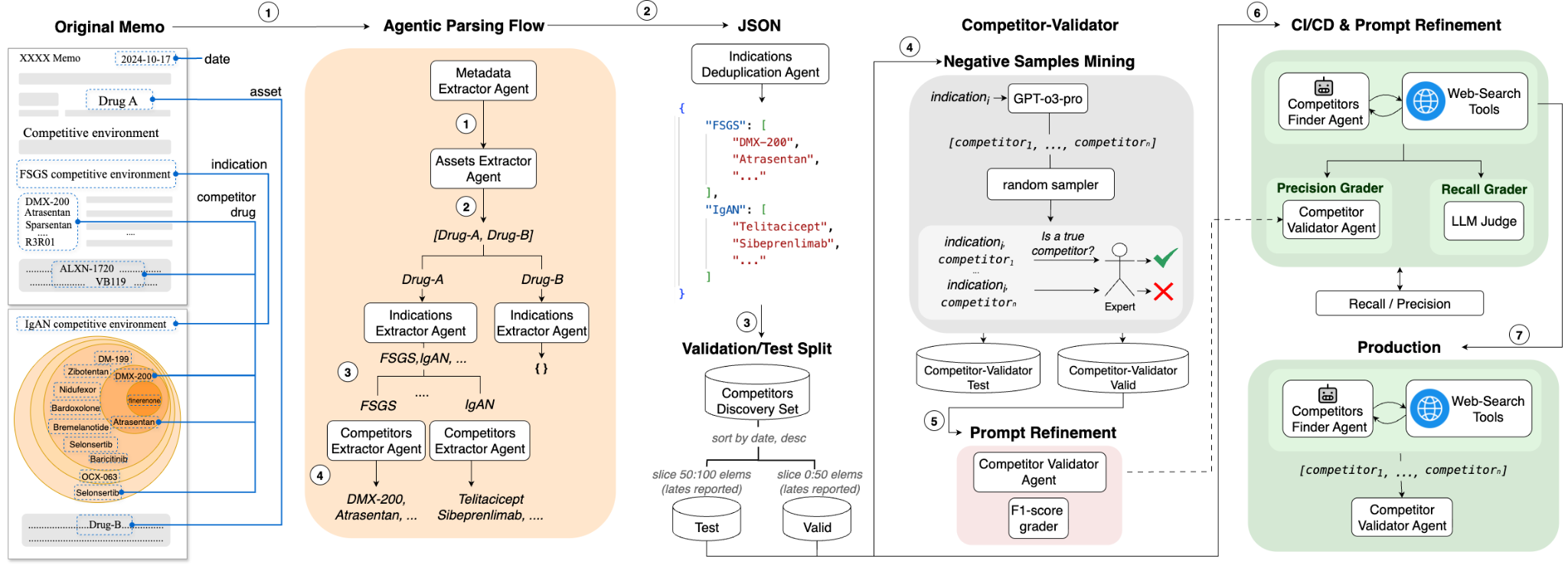
We started by looking at how human analysts work. We gathered five years of unstructured diligence memos from a private biotech VC fund. Each memo contained free-form text, embedded tables, low-resolution figures, and screenshots.
Our team built an AI agent system that parsed memos into a structured format:
- Identify each drug asset.
- Extract its targeted indications.
- Enumerate all relevant competitors for each indication.
- Pull structured attributes—modality, mechanism of action, development stage, company details.
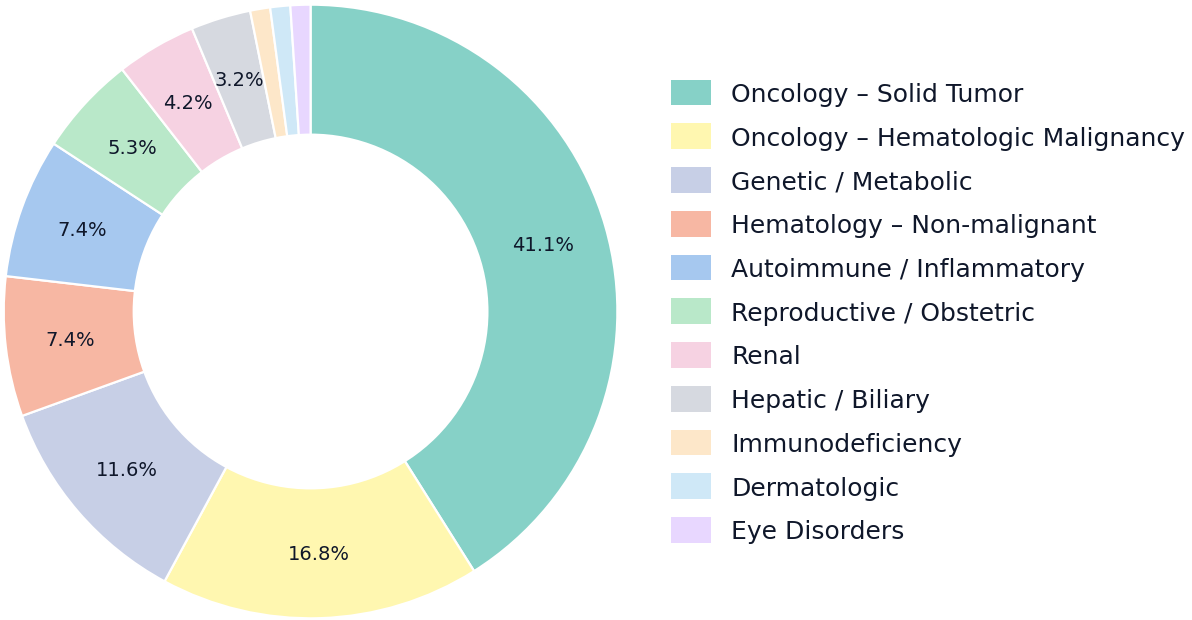
The memos span multiple therapeutic areas, and the resulting total set of indications was split into validation and test sets—the validation set is used for AI agents tuning, and the final quality is measured on the test set.
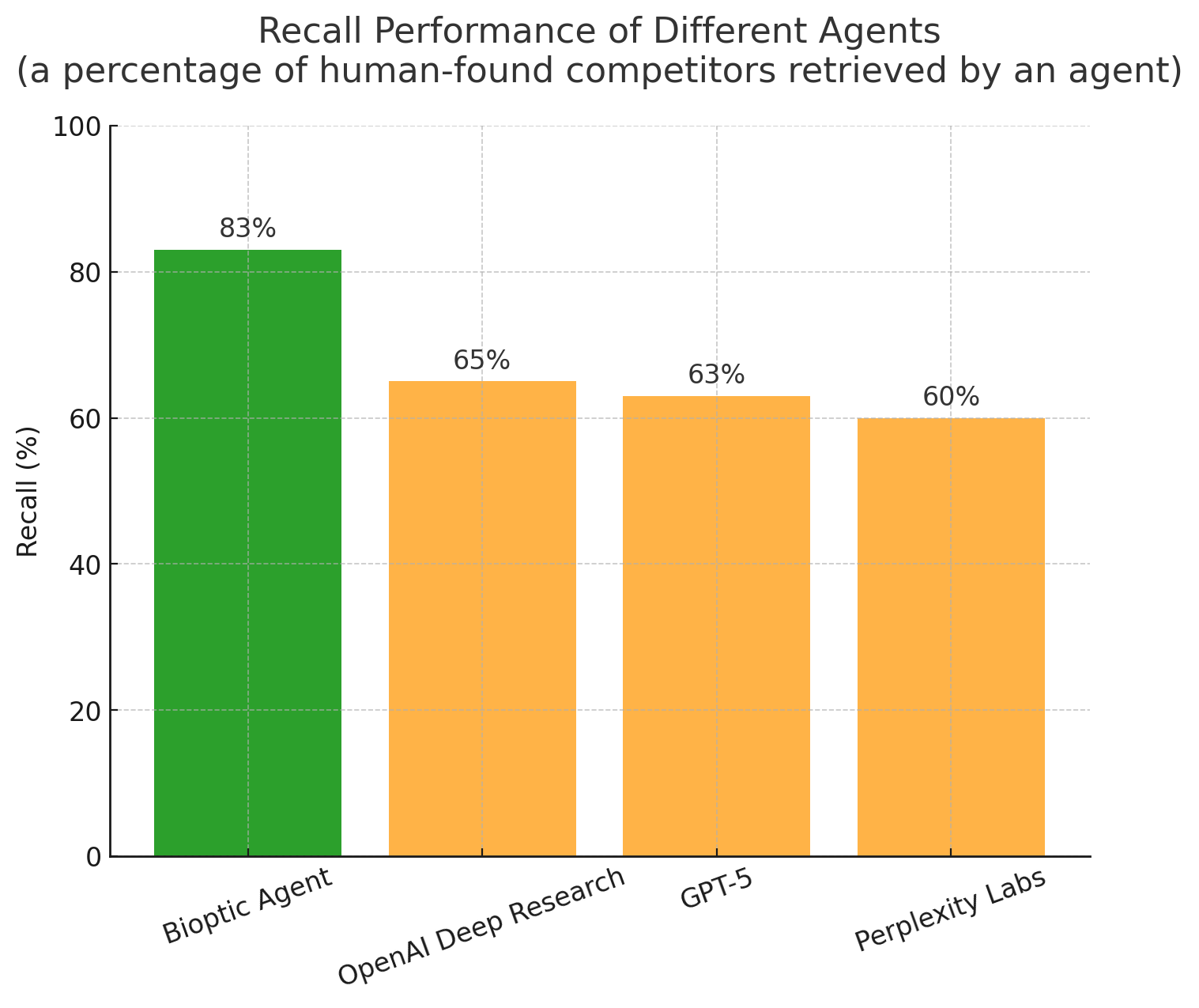
Outperforming ChatGPT Deep Research and Perplexity Labs
We tested our agent based on Gemini 2.5 Pro against state-of-the-art systems, including OpenAI Deep Research, Perplexity Labs, and GPT-5. Performance is measured as recall (or coverage) — a percentage of human-found competitors retrieved by an agent.
Every proposed competitor is checked by a Competitor Validator—an LLM filter tuned on biotech VC–labeled data, where each drug–indication pair is marked as a competitor or not a competitor. It strips out non-competitors, reducing hallucinations, so the final list is short, defensible, and high-precision.
Performance on hard examples
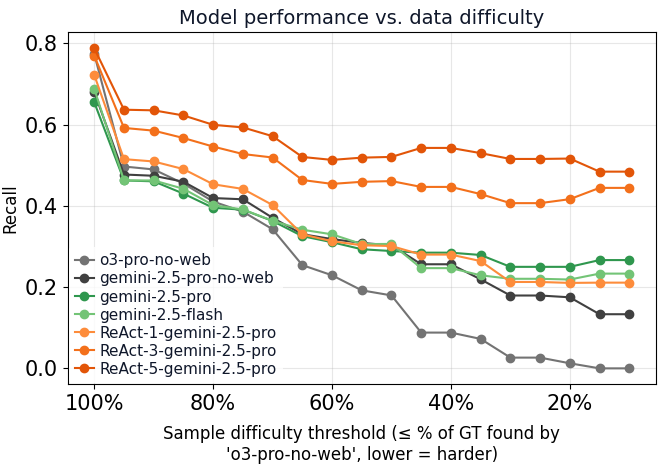
Additionally, we evaluated how different LLMs—including our agent—perform on hard cases, where the model does not simply memorize the competing drug names during training. To do that, we stratified the benchmark data by levels of difficulty based on the performance of the o3-pro with no web access.
With this analysis, we not only found that web-powered agents find many more competing drug assets, but also that an increasing amount of compute spent significantly enlarges the set of drugs found (see ReAct with 1-3-5 iterations).
One more thing — drug asset attributes extraction
It’s also essential to carefully extract relevant and up-to-date drug attributes (properties). To test the AI agent's reliability for this problem, we created an additional benchmark based on the duplicate human-created memos. As this is historical data, we turned the relevant issues into time-based success rate measurements. Here is the complete benchmarking data that again demonstrates that a specialized agent performs mostly better than a general Deep Research system:

For all attributes in the benchmark, the grading was performed via an LLM-as-a-judge that used web search as a tool to validate the specific information.
Voices from our partners
“As a biotech VC fund, we spend 90% of our time identifying attractive opportunities, analyzing clinical data and competitive landscapes, assessing commercial potential, performing asset valuation, and tracking developments. This process requires a team of well-trained PhD-level analysts. Additionally, precision and quality remain key. A single error can cost millions, while high-quality work can yield exceptional returns for investors. Since integrating LLM-based agents into our workflow, we've seen a major transformation in our analysis approach. Our efficiency increased multiple times both in high-level screening and deep due diligence. What took days of manual review can now be accomplished in hours without compromising analytical depth or accuracy.”
— Dmitry Kobyzev, Lance Bio
Read the paper
For more details, check out our paper—LLM-Based Agents for Competitive Landscape Mapping in Drug Asset Due Diligence—which is live on arXiv.